Paso 5: Sketch de Arduino
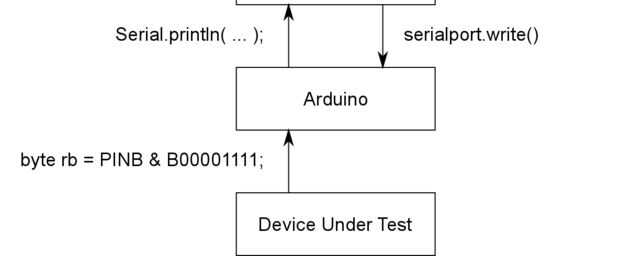
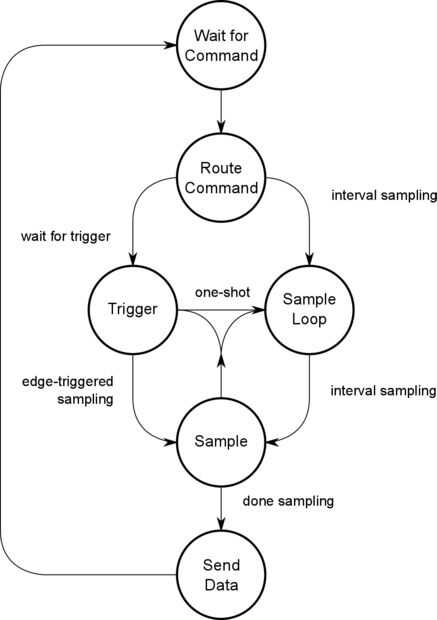
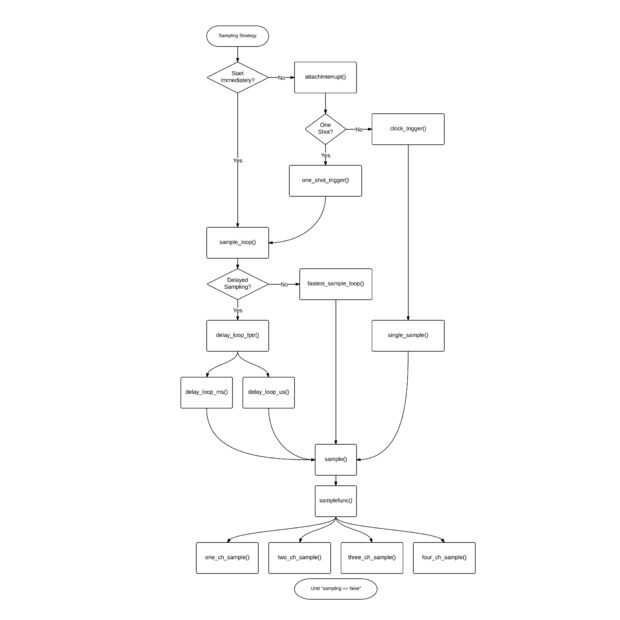
El sketch de Arduino contiene una máquina de estado que escucha los comandos serie a analizar, o inicia una sesión de adquisición de datos. Adquisición de datos se produce en forma de muestreo por flancos o basada en tiempos electorales. Tiempo base-interrogación puede ser trigged por un borde de levantamiento o caído.
Configurar el código para utilizar los siguientes pines de Arduino Uno (no debe para ser confundido con los pines del ATmega):
- Pin 2: Interrumpir 0, el gatillo
- Pin 8: Canal 1
- PIN 9: Canal 2
- PIN 10: Canal 3
- PIN 11: Canal 4
Circuito de comando
El comando serial sondea el puerto serie y espera personajes llegar. Cada comando es una cadena de caracteres que termina con un '%'. Cuando se analiza un '%', el búfer de cadena actual es enviado al router. (El cliente JavaScript enviará una cadena grande con todos los comandos).
Comandos:
- restablecer %: despejar las variables de contexto global
- % CH {1-4}: activar canales 1, 2, 3 o 4
- tiempo %n%: establece el tiempo de la muestra en ' n ' microsegundos.
- límite %n%: limitar el número de muestras de byte a ' n '. He añadido esto para darme alguna forma de administrar el tiempo de la muestra ya que no puedo interrumpir sin perder datos
- aumento %: muestra en el borde de levantamiento del gatillo
- % de caídas: muestra en el flanco descendente del gatillo (Nota muestreo funciona en ambos bordes, no exclusión mutua)
- una vez %: realizar un disparo paso a paso que se inicia el modo de votación
- Inicio %: compilar las opciones anteriores en variables globales, establecer los punteros a funciones y callbacks e iniciar el bucle de muestreo
Después de recibir el comando start % , el bosquejo configura las variables del contexto global y los interruptores de comando para toma de muestras de análisis. No puede ser interrumpida hasta que se completa y devuelve los datos, a menos que hagas un hard reset mediante botón o poder.
Muestreo basado en el tiempo
Si el usuario no ha seleccionado ningún disparo, el bosquejo determina que rutina de tiempo se debe utilizar. Hay tres:
- Tan rápido como sea posible: esto no tiene ningún retardo de velocidad máxima
- delay_ms(): esto utiliza la función delay()
- delay_us(): esto utiliza la función delayMicroseconds() , que tiene un límite máximo de 16.383 Estados Unidos.
El bosquejo asigna el funcionamiento a un puntero de función en lugar de utilizar if/else condicionales, esto acelera la ejecución y permite mejor abstracción.
Activación paso a paso
Si el usuario seleccionado el modo paso a paso, una rutina de servicio de interrupción (ISR) se establece en INT0 (el gatillo), para cualquier aumento, caída o cambio. El ISR a continuación separar la interrupción e invocar el muestreo basado en el tiempo especificado anteriormente.
Disparo de borde
Muestreo por flancos salta las rutinas de tiempo y recoge una muestra por gatillo. El bosquejo fija un ISR a INT0 similar al modo paso a paso, pero en lugar de separar la interrupción y llamar a la rutina basada en el tiempo, que simplemente recoge una muestra por interrupción. Como usted puede decir, si las interrupciones llegan más rápido que puede procesar el código, los datos se perderán. El límite es alrededor de 20us debido a la gran cantidad de código en las rutinas de muestra.
Muestreo de datos
Todos los métodos de invocación de muestreo utilizan las mismas funciones de adquisición de datos de bajo nivel.
Intento de limitar la sobrecarga, escribí cuatro diferentes rutinas de muestreo basan en el número de canales seleccionados y llaman a un puntero a función en lugar de if/else. Cada rutina tiene sus propias optimizaciones. El controlador de comandos iniciar % establece el puntero de función apropiada.
El bosquejo almacena las muestras en un búfer de bytes [1080]. Esto se traduce a poco 8640 muestras para un canal. El número de muestras de byte debe ser divisible por 2, 3 y 4. Ya que permite 1, 2, 3 o 4 canales activo, necesito particionar la matriz de amortiguamiento por lo que no tengo que realizar las comprobaciones de límite especial. El tamaño divisible por 12 es la mejor manera de manejar esto. No cumplir el código, pero lo hago en la interfaz HTML5: aviso que el control de muestras incrementa en 96 (12 * 8) y se detiene en 8640 (1080 * 8). Como bits se leen, son cambiados de puesto y llena en cada byte. Después de cada 8 bits, un byte se almacena en el índice y el índice se incrementa. Cuando el índice es igual a la profundidad de almacenamiento de información, muestreo completa y los datos. Si se selecciona un canal, datos se escriben en buffer [index]. Si se seleccionan dos canales, se escriben los bytes a buffer [index] y [índice + offset_2]; offset_2 = MAX_BYTE_SAMPLES * 1 / 2 y el índice es la mitad de lo que es en el modo de un solo canal. Escribe tres canales buffer [index], buffer [index + offset_2] y buffer [index + offset_3]; offset_2 = MAX_BYTE_SAMPLES * 1 / 3 y offset_3 = MAX_BYTE_SAMPLES * 2 / 3, el índice es 1/3 de ella es valor máximo en modo de un canal, etc..
Una vez el el buffer se llena o el índice excede el límite, poner fin a las rutinas de muestra y los datos se envían de vuelta.
Enviar datos
Los datos envían rutina devuelve el número de muestras recogidas (dividido por el número de canales utilizados) y datos binarios de los canales. Puesto que el usuario puede elegir cualquier configuración de canales, esta rutina decodifica los canales utilizados y por consiguiente les etiquetas (un poco de una molestia, en realidad, sé que hay una solución más rápida por ahí...). También soportes de la transmisión con begindata y enddata para el servidor de coordinar su analizador.
Nota
Puede observar que las variables globales gratuitas. Lo hice porque estoy tratando de conseguir una manija en cómo minimizar la huella de memoria para hacer espacio para más capacidad de muestra. Un área que necesita trabajo: utilicé un montón de objetos de cadena que crecen y decrecen, y tengo un montón de debug char * cuerdas flotando allí. He evitado utilizar malloc() y declaró el tampón de muestra en el montón. Encontré que la 1080 bytes es más puedo utilizar confiablemente sin que se caiga el bosquejo. Mi lista de tareas incluye entender gestión de memoria mejor en el ATmega y avr-loco / gcc y re-escribir este bosquejo para ser más predecible w.r.t. uso de memoria.









 utilizando una lógica y Arduino")



