Paso 1: Conexiones pares en Perl - métodos
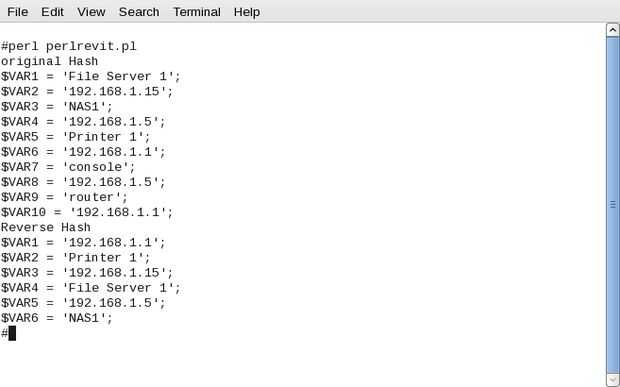
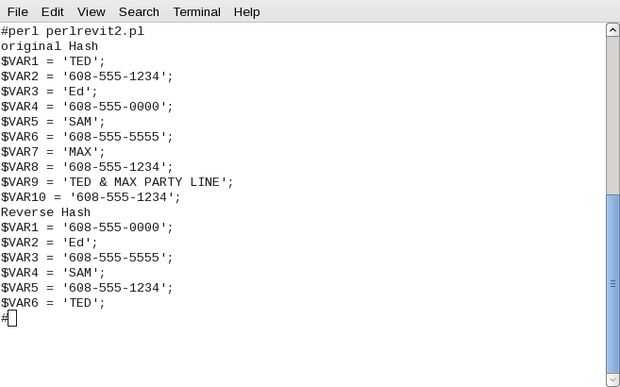
Considere el siguiente ejemplo:
Guías de teléfono proporcionan una lista ordenada alfabéticamente de nombres, lo que permite al lector conocer qué número de teléfono se asigna a una persona. También hay tal cosa como un "directorio inverso" que permite iniciar con el número de teléfono y el nombre de la persona asociada a ese número. (Útil cuando quiere averiguar quién es interrumpir su cena!).
Ahora el problema, vamos a decir se trabaja con una fuente de datos que no garantiza las asociaciones 1-1. Un ejemplo de esto sería teléfono líneas de partido. Un problema surge cuando se asocia con un número más de una persona. En Perl, si usted utiliza un array asociativo para búsqueda rápida, una versión invertida podría perder información. Las imágenes aquí muestran cómo usar la función inversa en un hash puede conducir a pérdida de información. En un ejemplo, tenemos una matriz asociativa de números de teléfono. Parece que hemos perdido la pista de "Max". En el otro ejemplo, tenemos Catálogo ficticio de dispositivos de internet conectado. En este caso hemos perdido la pista de "consolas". Otros indicios obvios de múltiples dispositivos con la misma dirección a un lado, la pérdida de la información hará evaluar con un simple array asociativo de problemático.
En una escala mayor, los registros se componen típicamente de varios campos. Un libro de teléfono, también incluye direcciones de calle. El campo dirección es útil para algunas búsquedas, pero no para otros. El campo de dirección sería un ejemplo de un valor asociado que no está indexado. Así, uno puede seleccionar los campos necesarios para la evaluación y un campo de identificador único que relaciona lo hacia el registro más grande. Estos campo seleccionado pueden ayudar con el apoyo de toma de decisiones y el campo id único puede entonces le permiten seleccionar de otros campos. Por ejemplo, tienes el teléfono móvil, pero quieres probar la línea de tierra.
Yo he invertido tiempo y esfuerzo a trabajar en Perl con este tipo de datos más fácil de hacer y me gustaría compartir mi solución. Un Perl "módulo" es perfecto para esto. Perl proporciona "módulos" que pueden utilizarse para encapsular los detalles de una aplicación para su reutilización. En el mundo de Perl encontrarás una vasta biblioteca de módulos de CPAN, como cualquier desarrollador puede hacer su propio módulo con esfuerzo marginal y ofrecen incluso hasta otros. Me gusta construir un módulo reutilizable por dos razones. En primer lugar quiero encapsular los detalles de implementación. En segundo lugar quiero hacer constante reutilización de la aplicación. Para utilizar un módulo uno simplemente incluye en su código utilizando la palabra clave use.
Las cosas que quiero implementar este módulo incluyen:
- Inicialización y miembro acceden / afirmar
- Impresión y depuración
- Añadir pares clave valor
- Quitar clave valor par
- Existe la clave
- Lista de todas las claves
- Invertir el valor de la clave par













