Paso 9: Desarrollar algoritmo (parte 2): regresión logística aplicando
Como ya he mencionado, ML (Machine learning) es una especie de cosa de reconocimiento de patrón. Separa 2 o más grupos dependiendo de sus características. Por ejemplo si tengo montón de números pares {(1,4),(6,3),(5,2)... (X, Y)}, quiero separarlos en dos grupos, un par que contiene que tiene número de suma menos 6 y el otro grupo contienen el resto. Una simple línea con ecuación X + Y < 6 va a hacer nuestro trabajo.
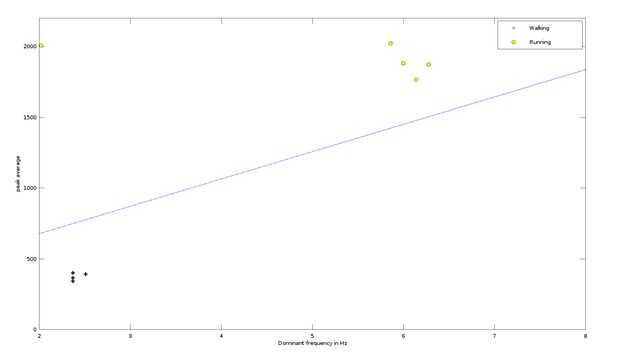
En nuestro caso X e Y será la frecuencia dominante y valores de pico absoluta promedio. En el script visualiza, que he adjuntado en el paso anterior, además de sólo visualización de datos, ayuda en informática estos dos parámetros también.
Frecuencia dominante se calcula utilizando el algoritmo de FFT. (https://en.wikipedia.org/wiki/Fast_Fourier_transfo...)
En ejecutar secuencia de comandos Visualize usted conseguirá resultados para frecuencia dominante y los valores de pico absoluta promedio. Copie y pegue en archivo de texto, en el siguiente formato.
Dominant_frequency_1, average_absolute_peak_values_1, 0/1...
0/1 en el lugar después de la segunda coma dice el método de regresión logística sean las características de los datos de caminar o correr datos. 1 para caminar y 0 para correr.
mire por favor el archivo de ejemplo que adjunto para el formato correcto.
Regresión logística es que, intenta separar esto caminar y correr los datos con la ayuda de una línea recta. Se muestra en la imagen. ¿Cómo sabe que esta línea va a separar estos dos conjunto de datos?. Aquí salta la matemáticas. Es un poco difícil de explicar por escrito, pero adjunto un tutorial de vídeo en la regresión logística por Andrew Ng, quien es un experto en este campo.
En el siguiente paso voy a hablar de secuencias de comandos que puede utilizar en sus propios datos, para obtener el algoritmo que no es más que una línea recta separando estos 2 conjuntos de datos.













