Paso 4: Mejoras y modificaciones
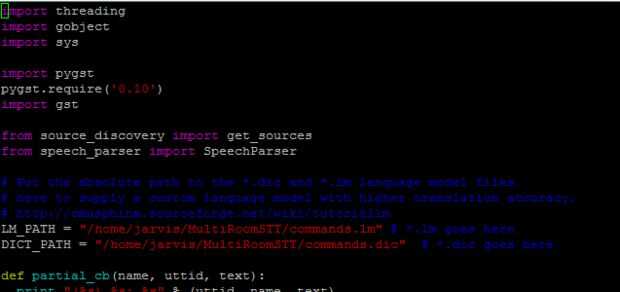
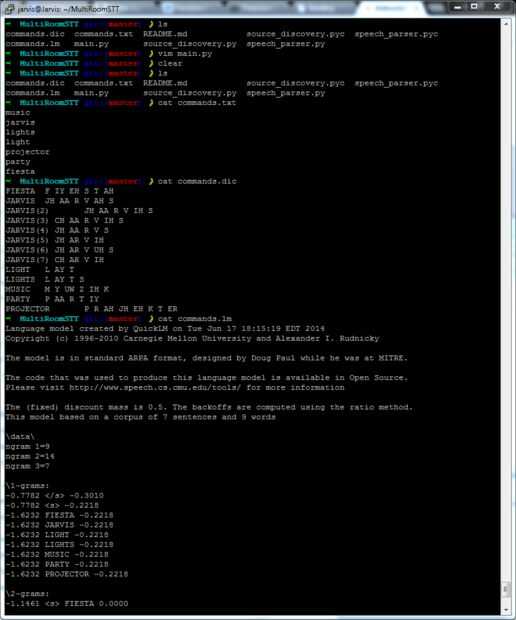
Nos dimos cuenta que la transcripción del defecto realizada por esfinge es, sencillamente, terrible. Por suerte, es bastante fácil de solucionar este problema mediante la creación de un modelo de lenguaje personalizado. Esto puede restringir el rango posible de las palabras identificadas, dando como resultado menos errores de traducción.
Siga las instrucciones en el enlace de arriba para generar el modelo de lengua y descargar los archivos creados en la carpeta MultiRoomSTT. A continuación, abra main.py y proporcionar las rutas absolutas a cada archivo en las variables LM_PATH y DICT_PATH. la secuencia de comandos utiliza estos modelos de lengua la próxima vez que se ejecuta. Usted debe ver que un enorme incremento de transcripciones correctas siempre y cuando el discurso se transcribe sólo utiliza palabras de este modelo.
Cómo funciona el código:
Cuando main.py primero, busca una lista de fuentes de audio a través de la escritura de la source_discovery.py. Que script ejecuta el comando en el terminal "pacmd lista de fuentes" y analiza las fuentes de audio de los resultados, manteniendo el nombre, identificación y ruta de autobús de dispositivos de entrada. El nombre es útil para la legibilidad humana, y el ID es lo que utilizamos para identificar qué fuente de audio para grabar en.
El campo de ruta de autobús es el más interesante - contiene información acerca de puerto que el dispositivo de entrada está enchufado y puede ser referencia para determinar qué habitación un dispositivo USB es grabación de. Por ejemplo, si usted quiere tomar el audio de su sala de estar y sabes el dongle está enchufado en el puerto 6 del concentrador USB que esté conectado en el puerto 4 en su computadora, busque "usb-0:4.6:1.0" en el autobús de camino y encontrarás el ID de la mochila. Ruta de bus es persistente a través de los enchufes/desconecta y luego se reinicia, así que no tienes que ir probando IDs dispositivo al azar para encontrar el micrófono que estás buscando.
Después de reunir información de la fuente, la secuencia de comandos crea un objeto SpeechParser para cada fuente de audio y ejecuta en un bucle principal. La clase SpeechParser abstrae lejos todo el código desordenado de GStreamer: configuración de la tubería, configuración de propiedades de devolución de llamada y enlazan a la fuente de audio a PocketSphinx.
Una vez que se ejecuta el bucle principal, las tuberías escuchar en sus respectivas fuentes de audio y pasarlas a través de la esfinge (más info sobre eso aquí). Cuando la esfinge es en medio de la transcripción de una secuencia de fonemas, envía las devoluciones de llamada a través de SpeechParser a la función de partial_cb pasó con lo que piensa que escucha. Cuando el micrófono detecta silencio y Esfinge acabados análisis del discurso, el resultado se pasa a través de SpeechParser a final_cb.



")

")

")





