Paso 6: Configurar una secuencia para almacenar los datos en data.sparkfun.com
Para los efectos de este proyecto, elegimos utilizar data.sparkfun.com para almacenar nuestros datos de los sensores. Elegimos este lugar debido a la facilidad de uso de la API, de habilidad para descargar como un archivo CSV y el espíritu del código abierto de sparkfun. Yay Sparkfun!
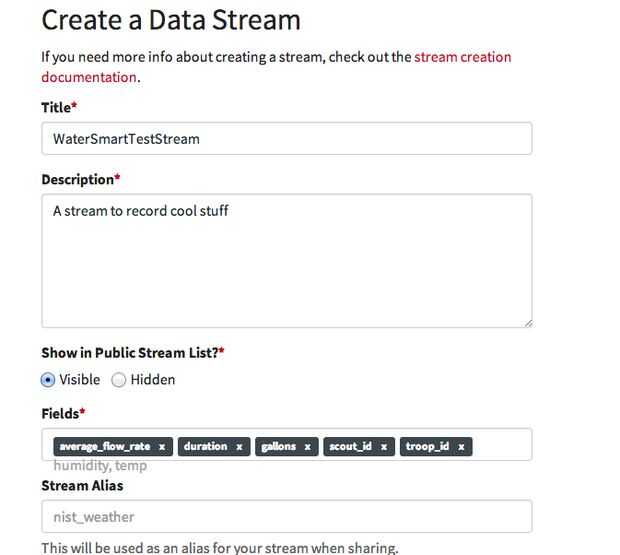
Para configurar un repositorio para almacenar los datos, crear una nueva "fuente" en el sitio data.sparkfun.com. Utilice los siguientes nombres de columna.
average_flow_rate, duración, galones, scout_id, troop_id y entrar en el resto de la información cómo te gusta.
El seguimiento de todas las claves que utilizará. Va a venir bien.
Cuando la corriente está configurado, prueba introduciendo el siguiente url en el navegador:
http://Data.Sparkfun.com/Input/ [su PUBLIC_KEY]? private_key = [su PRIVATE_KEY] & galones = 0,56 & avg_flow_rate = 0 & duración = 3067 & scout_id = 2 & troop_id = 4
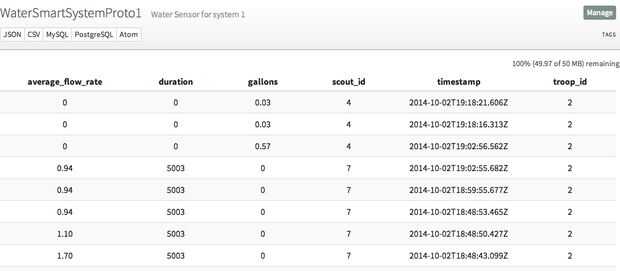
Esto debe insertar una fila en su corriente de nuevo. Siempre puede comprobar el contenido de su corriente de aquí:
https://Data.Sparkfun.com/streams/ [clave pública]
¡ Felicidades!
Por lo tanto, ahora tienes una corriente de la fuente (corriente de sincronización de Pinoccio) y una secuencia de destino (data.sparkfun.com). El truco es obtener los datos seleccionarlos de uno a otro. Para ello, utilizamos Python. (Pase al siguiente paso)
Nota: hemos optado por la piezo (fregadero y accesorios) escritura exclusivamente a las columnas de frecuencia y duración del flujo y la escritura de efecto hall sensor (medidor principal) exclusivamente a la columna de galones. Todas las columnas no exclusiva simplemente se establecen en cero.
Fueron capaces de Visual prueba de Tara del sistema mediante la comparación de la corriente en la cañería - tal como aparece en data.sparkfun.com - con el flujo del aparato - como también informó en sparkfun - y tiene 99% de precisión al correlacionar las dos!

")











