Paso 2: programación
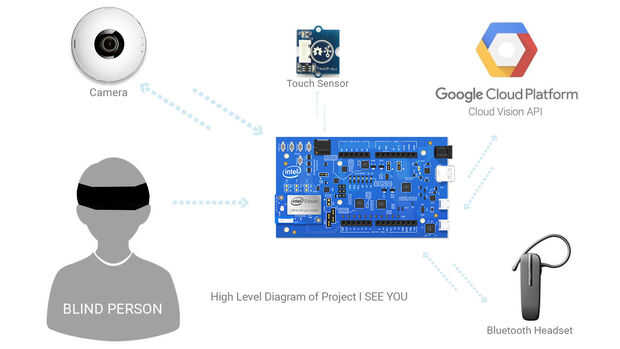
Estamos utilizando el lenguaje python para programar, antes crear una cuenta de la consola del cloud de google https://console.cloud.google.com entonces hacer un proyecto y permiten visión cloud API para ese proyecto.
DETALLES capacidad está en las instrucciones disponibles aquí https://cloud.google.com/vision/docs/quickstart
Biblioteca de cliente Google Cloud Vision API para Python usando masilla ternminal
instalación de PIP--actualización google api python cliente
https://developers.Google.com/API-Client-Library/p...
hacer un python de archivo dentro de intel edison y escribir este código
https://github.com/GoogleCloudPlatform/Cloud-Visio...
Añadir código de sensor táctil disponible aquí
https://software.Intel.com/en-US/IOT/hardware/Sens...
para conexión de cámara se puede utilizar este tutorial
siguiente código es un script en python simple que alimentan la entrada de sensor táctil y convertir una imagen en texto con la ayuda de la visión de google API
importación base64
Import os import re import sys
desde el descubrimiento de importación googleapiclient
de errores de importación googleapiclient
importación nltk
de nltk.stem.snowball
importación de EnglishStemmer de oauth2client.client
importación GoogleCredentials
importación de redis
DISCOVERY_URL = ' https://{api}.googleapis.com/$discovery/rest?version={apiVersion}' # noqa
BATCH_SIZE = 10
tiempo de importación
pyupm_ttp223 de importación como ttp223
toque = ttp223. TTP223(0)
mientras que 1:
Si touch.isPressed():
clase VisionApi:
"" "Construir y utilizar el servicio de Google Vision API."
DEF __init__ (self, api_discovery_file='vision_api.json'):
Self.Credentials = GoogleCredentials.get_application_default() self.service = discovery.build ('v1', 'visión', discoveryServiceUrl, credentials=self.credentials = DISCOVERY_URL)
DEF detect_text (self, input_filenames, num_retries = 3, max_results = 6): "" "usa la API de visión para detectar texto en el archivo dado." "" imágenes = {} para el nombre de archivo en input_filenames: con open (nombrearchivo, 'rb') como image_file: imágenes [archivo] = image_file.read()
batch_request = [] de nombre de archivo en imágenes: batch_request.append ({'imagen': {'content': base64.b64encode (images[filename]).decode('UTF-8')}, 'características': [{'tipo': 'TEXT_DETECTION', 'maxResults': max_results,}]}) solicitud = self.service.images () .annotate (cuerpo = {'solicitudes de': batch_request})
tratar: respuestas = request.execute(num_retries=num_retries) si 'respuestas' no en respuestas: volver {} text_response = {} para el nombre de archivo, respuesta en zip (imágenes, responses['responses']): Si 'error' en respuesta: imprimir ("API Error de % s: %s" % (nombre de archivo, respuesta ['error'] ['mensaje'] si 'mensaje' en respuesta ['error'] más '')) continuar si 'textAnnotations' en respuesta: text_response [archivo] = respuesta ['textAnnotations'] más: text_response [archivo] = text_response return [] excepto errores. HttpError como e: impresión ("Http Error de % s: %s" % (nombre de archivo, e)) salvo error como e2: imprimir ("clave de error: %s" % e2)
para más información sobre código goto https://github.com/GoogleCloudPlatform/cloud-visi...







")



")
")
